ParKomfort: Safe Parking Recommendation
12 Jan 2022Finding a street parking spot during peak hours is always headache due to availability, price and safety concerns. The ideal parking spot would provide sense of comfort and safety.
Current parking spot-finding products (Parkopedia and ParkMobile) offer only location and price data with no regard for crime or policing. Users have to rely on other systems to search for safer parking options, thus creating a non-unified experience. This project considers the street parking tickets in a different perspective, as well as the crime elements, and tries to bring peace of mind to the users.
1 INTRODUCTION AND MOTIVATION
The objective of this project is to develop a parking recommendation application based on user preferences to make data-informed decisions to locate a parking spot in big cities such as NYC. The application will utilize multiple publicly available datasets (NYC parking violation, parking meter dataset, and NYPD complaint data) to recommend parking spots based on policing and crime risk factors.
2 LITERATURE SURVEY
2.1 Parking recommendation algorithms and designs
Most of the literature uses the spatiotemporal analysis approach to predict availability of on-street parking either through real-time data collected by infrastructures such as parking meters and parking lots, or build- ing machine learning models trained on large datasets. This first approach heavily relies on live data to retrieve available parking space near the user’s location. It offers personal preferences, such as walking distance, driving distance, available parking space, and parking fees. Furthermore, users can adjust the weight to get customized experience.[Chen and Chiu 2017] Many recommendation systems have been developed. In our project, We improve on current parking recommendation services by including risk factors (crime rate and policing) into consideration.
When real time data is not readily available, machine learning models trained on large data sets are often used to make predictions of parking space availability and recommend to the users.[Awan et al. 2020] In particular, spatial analysis units (i.e., point, street, census tract, and grid) are used to examine the impact of spatial scale in classic machine learning predictive models.[Gao et al. 2019]
2.2 Definition of risk factor and how it is measured
In this project , the risk factor is related to the amount of crime and policing. Crime-related risk is directly associ- ated with personal/property loss due to auto burglary, vehicle theft, and vandalism. Policing-related risk comes into play when the driver forgets the parking restriction or is not available to move the vehicle, which leads to tickets or towing charges.
There are many time and location-related risk fac- tors, such as the type of parking: street, underground parking lot, as well as the visibility and accessibility of the parking location, time and duration of the parking, since night reduces visibility, and duration increases the number of chances presented to criminals to execute a crime or for police to issue a fine[Nourinejad et al. 2020]. Subsequently, higher valued vehicles present better targets for criminals (and police). Finally, socio-economic factors such as population density, demographics, local culture, economic conditions, as well as attitude toward crime all affect crime rate[FBI 2011].
Spatial analysis has been used to identify the hot or cold spots. Kawamura et al. used Getis-Ord G statistics to identify hot spots of high truck parking violations in the Chicago metro area, and showed density variation across downtown to suburbs. G statistic for spatial visualization could be potentially incorporated into risk factor calculation in the parking recommendation and visualize the amount of crime and policing [Kawamura et al. 2014].
3 PROPOSED METHOD
3.1 Intuition
Since no current methods provide security outlook for parking, our method provides inherently better options for parking selection. Our project will help minimize the chances of negative events (such as vehicle related crime or parking ticket) and provide sense of safety to the users.
3.2 List of innovation
- Providing security outlook for parking
- Providing customizable User Experience to accommodate individual risk tolerance of all users
3.3 Approach
3.3.1 Data gathering
The data used for this project came from 3 different source, i.e. NYC parking tickets (dataset 1), NYC street parking meter (dataset 2), and NYPD complaint data (dataset 3).
Dataset 1 is the New York parking tickets data from NYC OpenData for the fiscal year 2021 and 2022 (about 1.2 GB), which contains tickets issued in year 2020 and 2021. It provides locations of parking violations as well as valid parking duration. Combined with dataset 2, it provides available parking spaces near destinations. Using dataset 3 we extracted vehicle-related crimes near the destination. With these datasets, information related to parking availability and risk factors can be derived and used in parking recommendation.
3.3.2 Data wrangling
The crime database contained all complaint data of NYPD, which needed to be filtered for vehicle related entries only. Additionally, even though dataset 1 and dataset 2 has large amount of data, some are unusable. The data is deemed unusable for several reasons: 1) The locations are scattered all over the world, even if the data is filtered to display NY license place. 2) incomplete addresses (missing city, or state, or house number). 3) ticket issuance date in the future or several years back. The approach to filtering out those data are 1) removing the address not in NYC, 2) try to get the geolocations if we have enough information such as street/city/state, regardless of the house number, and 3) Focus on the ticket issuance date of the given fiscal year. After filtering out unusable data, we focused on getting geolocations and street addresses for the project. Unfortunately, the dataset 1 (parking tickets database) provides only street addresses. We used python library geopy to convert the street addresses to latitude/longitude pairs. However, the throughput of the API severely limited the amount of the data that can be processed within the project timeline.
A few methods were used to try to get as much conversion as possible: 1. Getting the list frequently appeared street name and then run them in the order of most to least. 2. Run the different set of street names on different machines simultaneously. 3. Make sure that each request have at least one second apart in between so it does not overwhelm the API. They worked. Similar issue happened with dataset 2(NYC parking meter database) as it only has geolocations and no address. We then run a reverse search using the same python geopy library.
3.3.3 Data Analysis
We also implemented an unsupervised machine learning algorithm, k-means clustering, to identify similarities among the parking ticketing data. Each parking citation will be assigned to a cluster and will map to police precincts. It will enable the calculation of the distribution of tickets per precinct within a cluster, allow- ing us to identify the precincts which are more likely to issue parking violations.[Lin et al. 2019]. The heat map visualization of parking violations will also be produced for in-depth analysis and data-driven decision-making.
The cluster technique of the k-means algorithm can also be applied to the crime data to identify the crime trend and zoning knowledge[Thota et al. 2017][Wang et al. 2020].The k-means algorithm will be implemented as shown in Algorithm 1. To determine the optimum number of clusters, we graph the relationship between the number of clusters and scaled within cluster sum of squared errors (WCSS) then we select the number of clusters where the change in WCSS begins to level off (elbow method).[Lin et al. 2019].
Additionally we assigned risk level to each parking meter to provide adjustable level of risk tolerance, when searching for parking. Each precinct was categorized into 4 risk levels based on number of cases of vehicle larceny. Then, we utilized K-nearest neighbours algorithm to learn precinct class of parking violation data, as well as crime data, and predict the precinct of each parking meter. Subsequently the risk level of precinct can be assigned to meters.
3.3.4 User Interface
We built a flask app to display the maps of the NYC with heatmaps for crime and parking data and search page for parking meters. It was infeasible to display heat density map of crimes and parking violations due to processing and rendering requirements so we aggregated data down to police precinct level. The precincts are highlighted on the map and are colored by crime and violation statistics, and represent relative security risk. Each precinct can be selected or searched for additional comparative data.
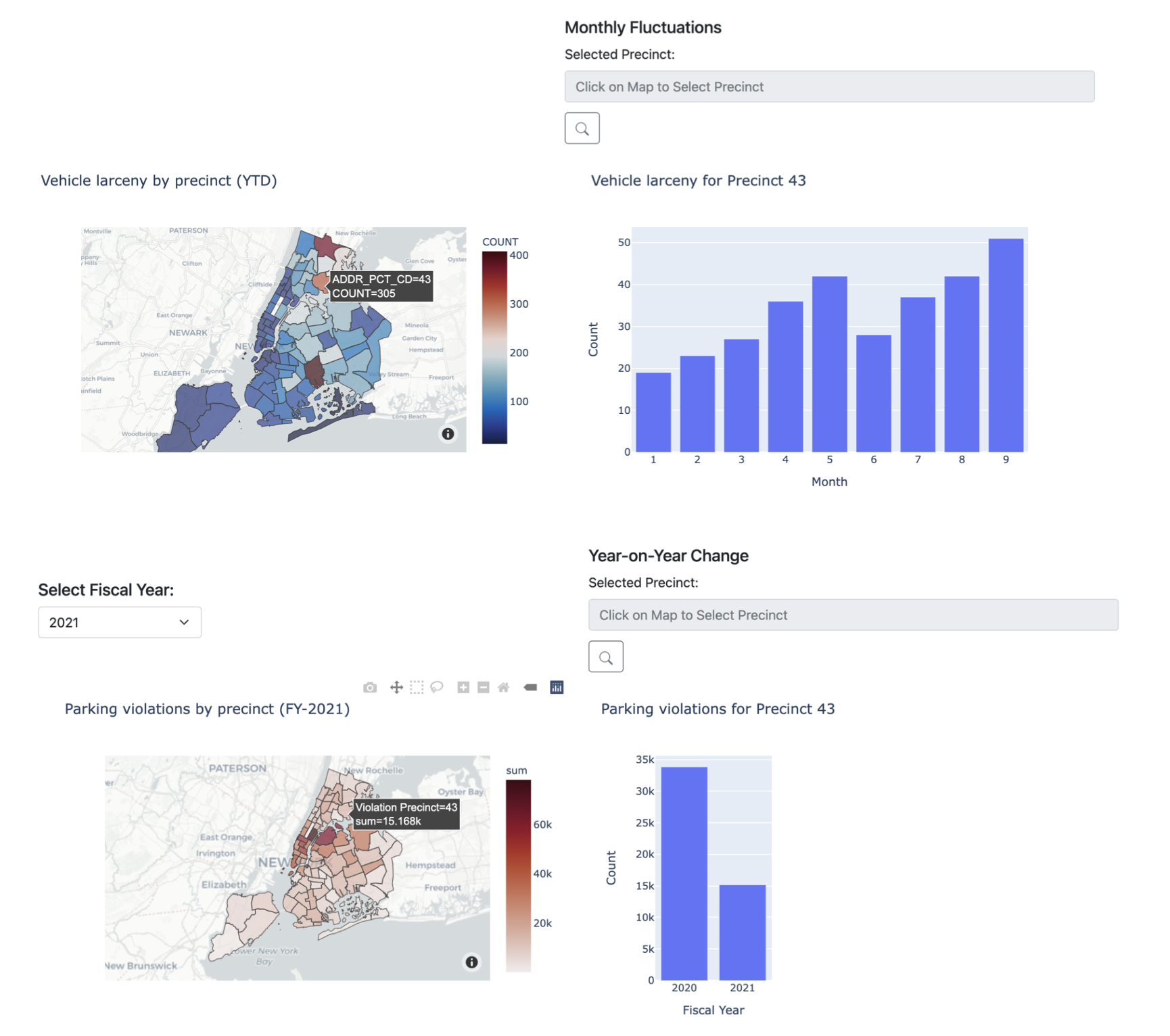
Figure 1. Top: Screenshot for larceny; Bottom: Screenshot for parking violations
The search page takes any NYC address and looks for closest parking meters. Search through 15 thousand parking meters may take considerable time so we implemented 2-level search to first limit the search radius to user defined radius, then second layer calculates euclidean distance from desired address to these meters, ranks them and displays 10 closest on the map. In case of the desired address being in high risk zone, the search algorithm would output results in nearby, safer precincts within the set radius.
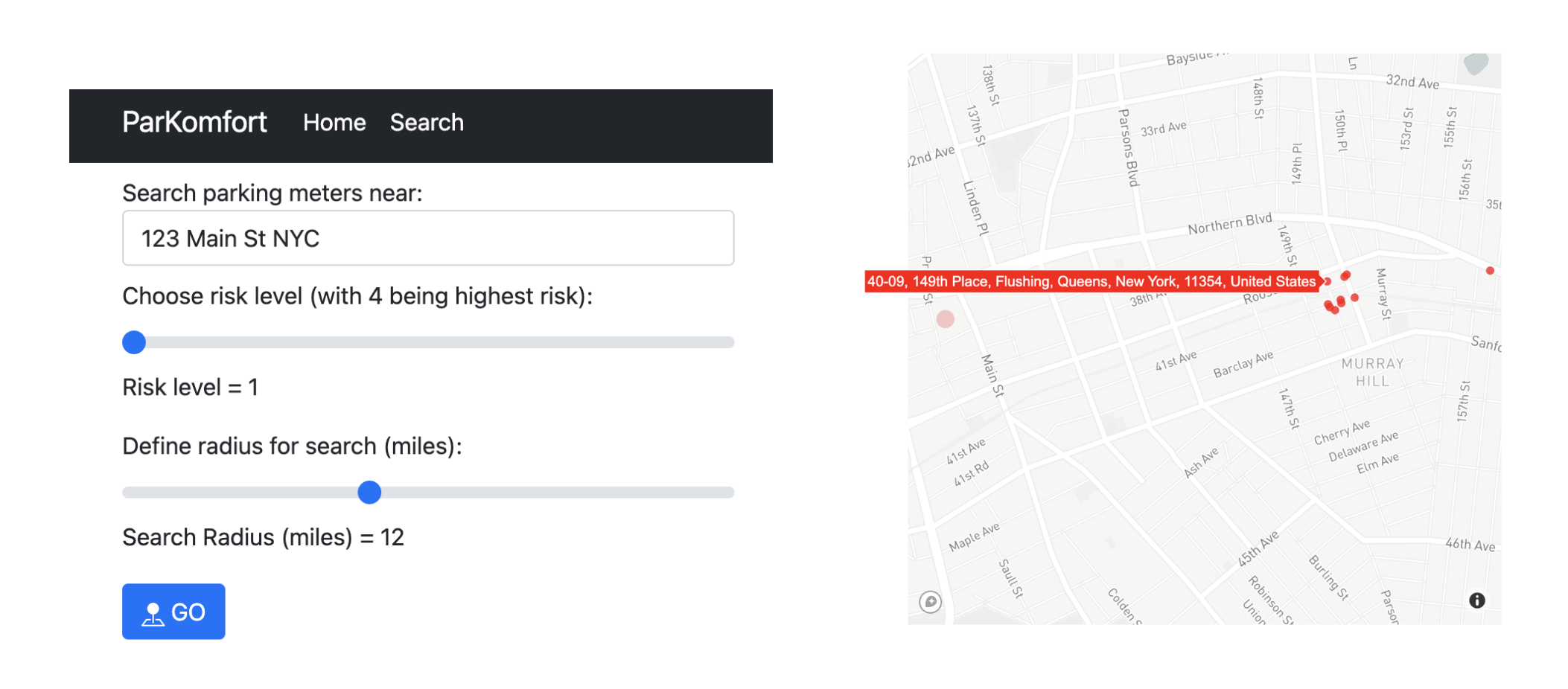
Figure 2. Screenshot searching for closest 10 parking meter locations
4 EXPERIMENTS/EVALUATION
4.1 Hypotheses
- Compare and contrast the effectiveness of the predictive algorithms implemented based on the past data in regards to places to park (considering the parking tickets, and crime location data)?
- Is there strong the correlation is there between amount of parking tickets issued versus crime rate?
- Is User Interface usable and intuitive?
4.2 Plans of Observations
This can be accomplished in the following ways:
- Subscribe to social media for local news about crimes at the area
- In person observation at locations with high parking tickets issued
- Depends on the frequency of the NYC open data updates, we can keep track of the new data to test the hypothesis over a span of 1 month.
- Using user reviews to test UI usability
4.3 Evaluation
We first performed exploratory analyses on the cleaned vehicle larceny and parking violation datasets.
On vehicle larceny data in NYC, Fig. 3 showed the distribution of vehicle-related crimes over the month(YTD), week, and day. It was found summer season sees the highest occurence of crimes throughout the year, and most vehicle larceny happens starting from 1 pm till mid- night. There isn’t much day-to-day variations through- out the week.
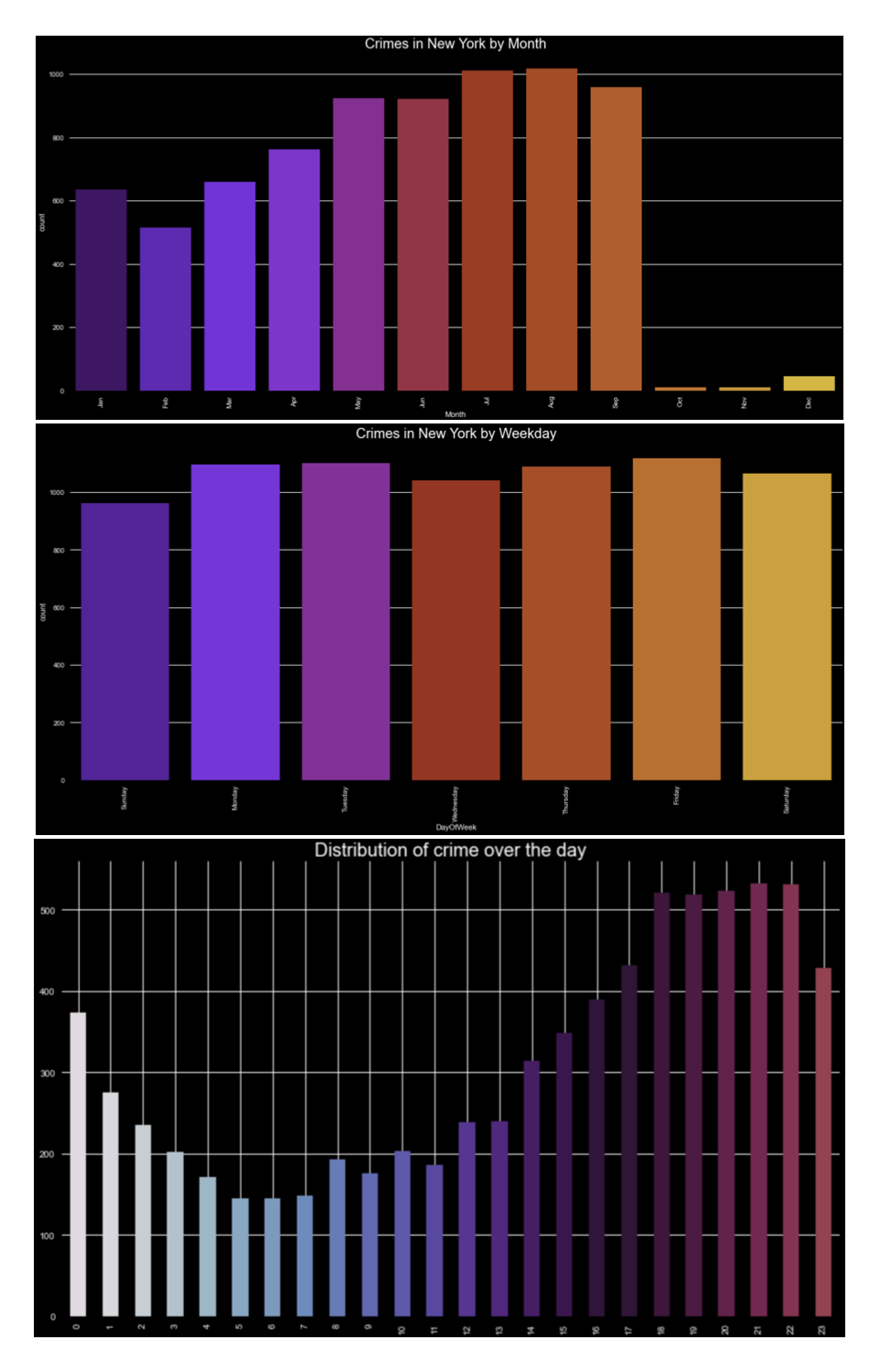
Figure 3. Overview of vehicle larceny data in NYC
Fig. 4 displays the heatmaps for vehicle larceny data in NYC. Based on heatmaps, it is observed that precinct- level distribution is aligned with density, and crime data shows geographical concentrations most residing north and south of NYC.
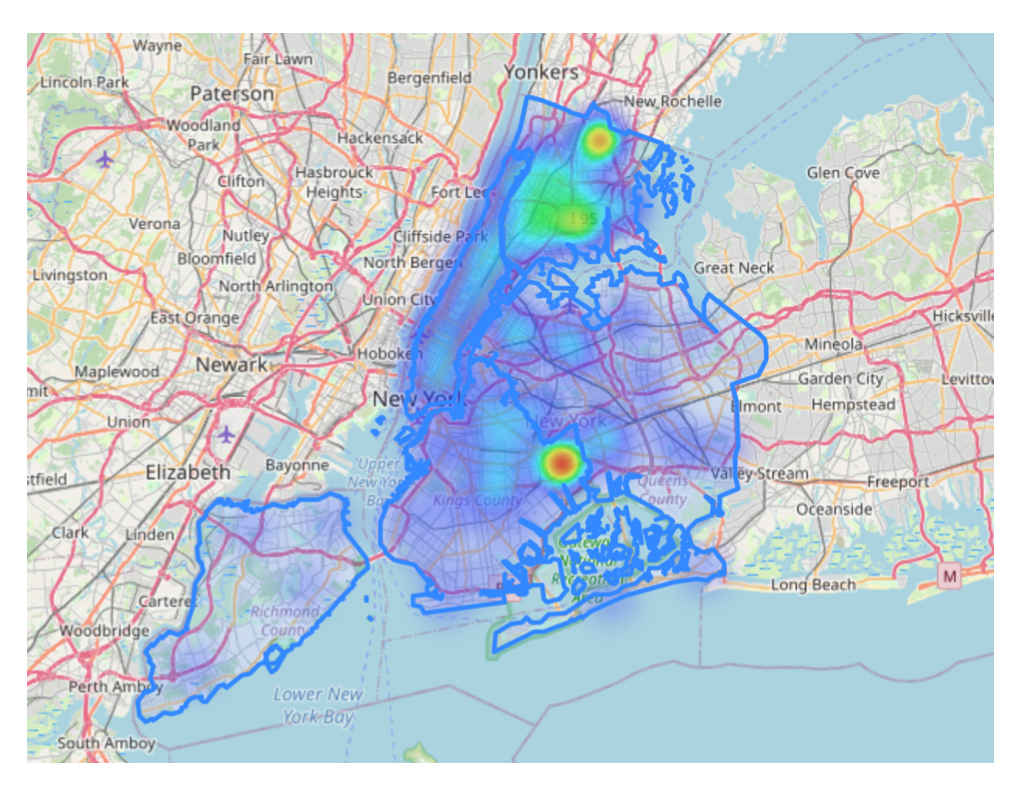
Figure 4. Heatmap of vehicle larceny data in NYC
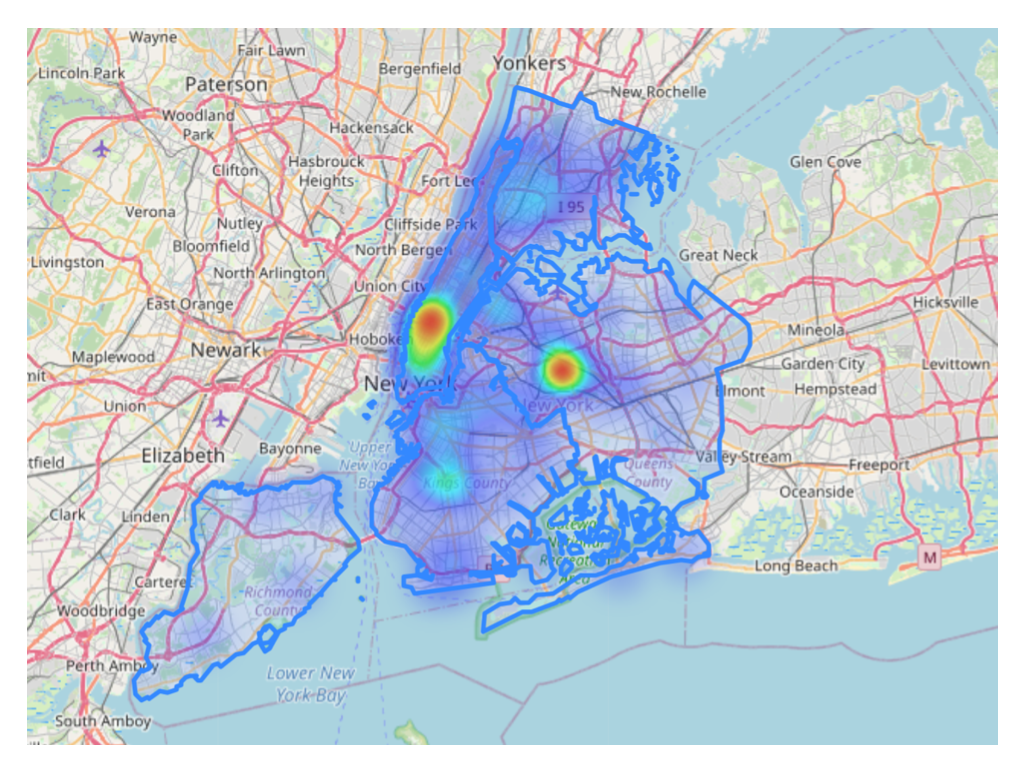
Figure 5. Heatmap of parking violation data in NYC
Regarding parking violation data for the year 2020 and 2021, Fig.6 shows the distribution of parking violations for vehicle make/type, as well as over the month, week and day. It could be seen that some vehicle brands and types experienced high parking violations than others. This could be due to reasons such as market share and consumer preferences. The distribution of violations over the month, week and day provides more insights for our applications. It could be seen that during the first half of 2020 and 2021, there aren’t many parking viola- tions recorded, which is probability due to the influence of COVID-19 pandemic (either fewer people commut- ing to the city or enforcement agency stopping issuing tickets). Weekday sees the most occurrences of parking violations, and most parking tickets were issued from 6 amto6pm.
Fig. 5 displays the heatmap for parking violation data in NYC. Different from the larceny, parking violations shows different geographical distribution. Based on the heatmaps similarity, it is observed that precinct-level distribution is aligned with density. However, parking violation data shows geographical concentrations most residing east and center of NYC. The difference from larceny could be attributed to the fact that Manhattan (east of NYC) and Brooklyn (center of NYC) have more commuter and vehicle presence.
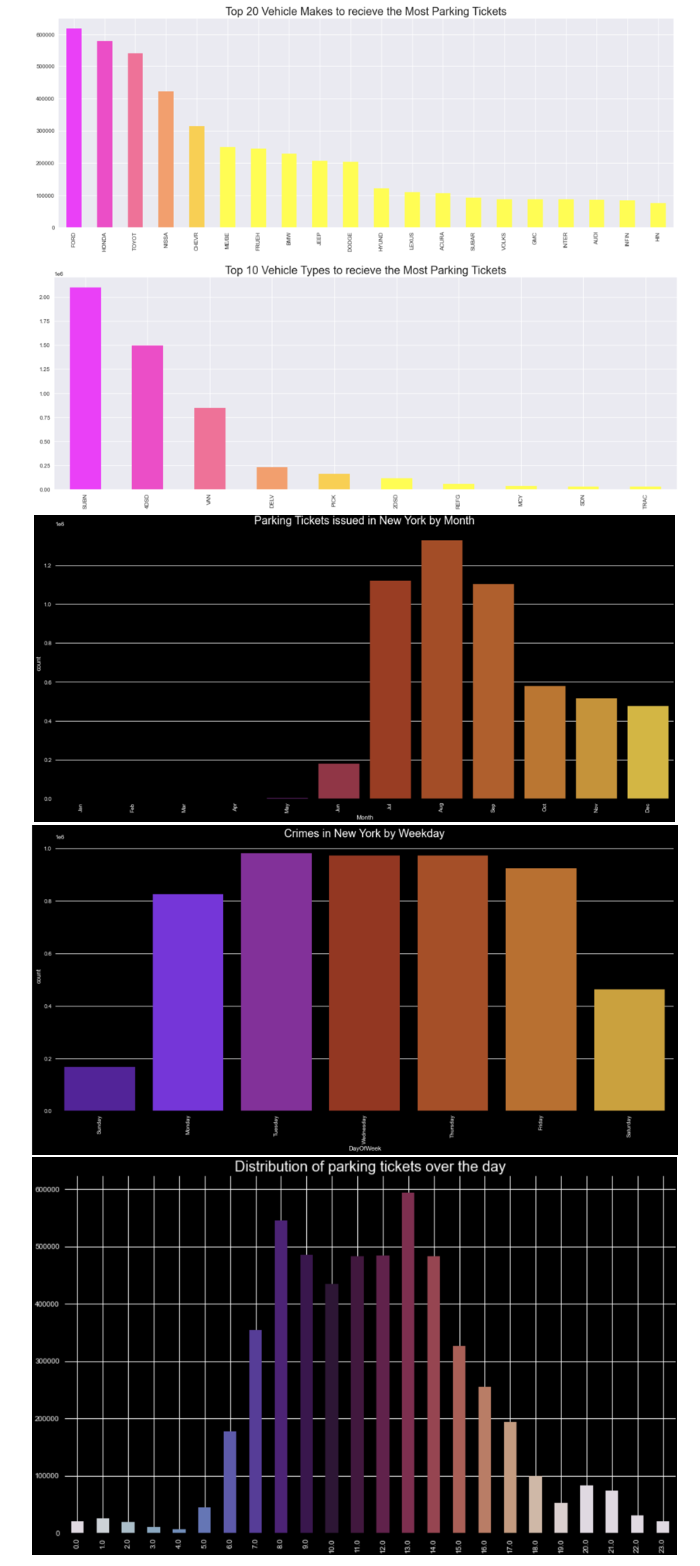
Figure 6. Overview of parking violation data in NYC
K-means clustering algorithms were used to analyze vehicle larceny and parking violation data.
On vehicle larceny data, it was found from the elbow method, the optimum cluster size is 25, with WCSS 2.72 and the clusters were plotted as shown in Fig.7. Based on the results, the vehicle-related crimes showed geographical preferences.
On parking violation data, it was found from the elbow method, the optimum cluster size is 25, and the clusters were plotted in Fig.8. The WCSS was found to be 0.2*1e7.
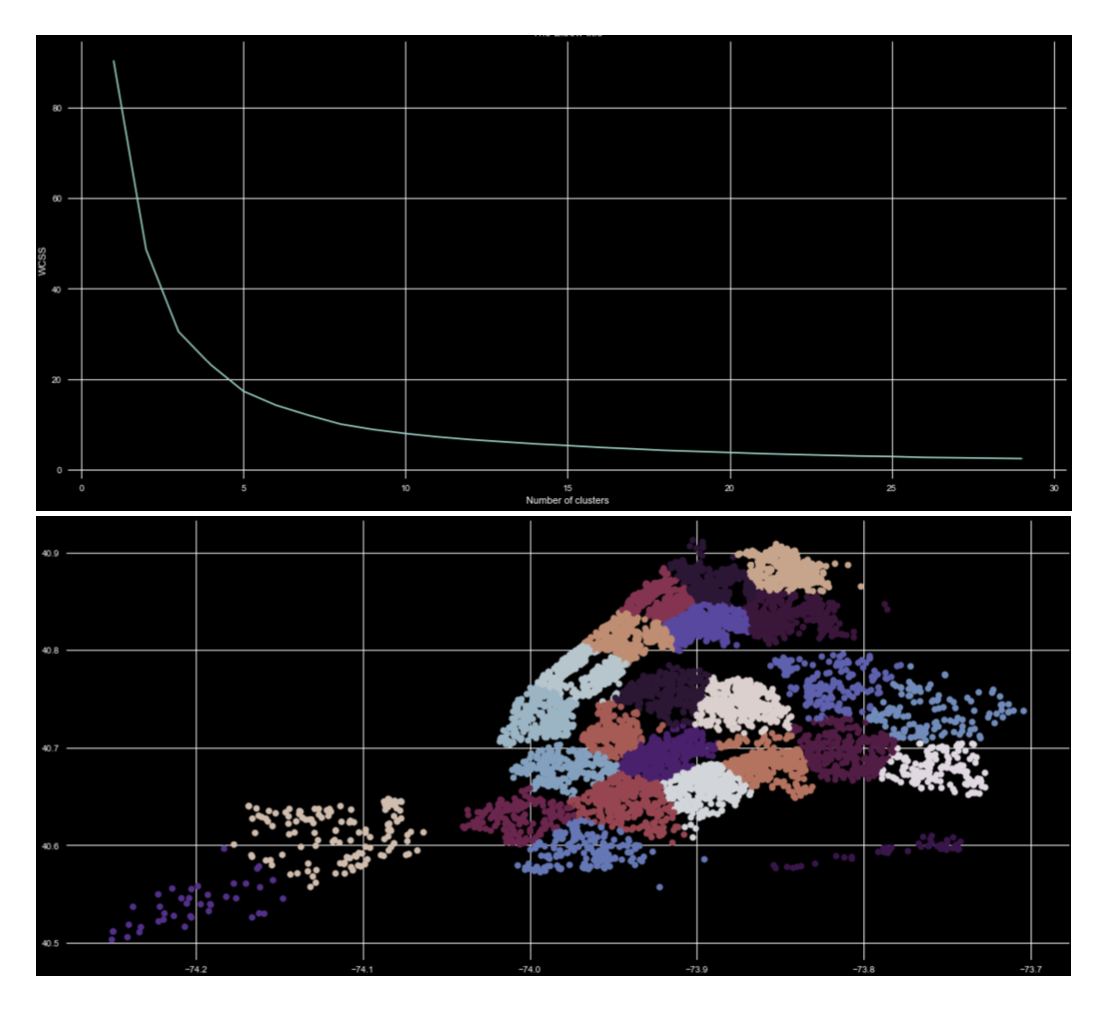
Figure 7. K-means clustering on vehicle larceny data
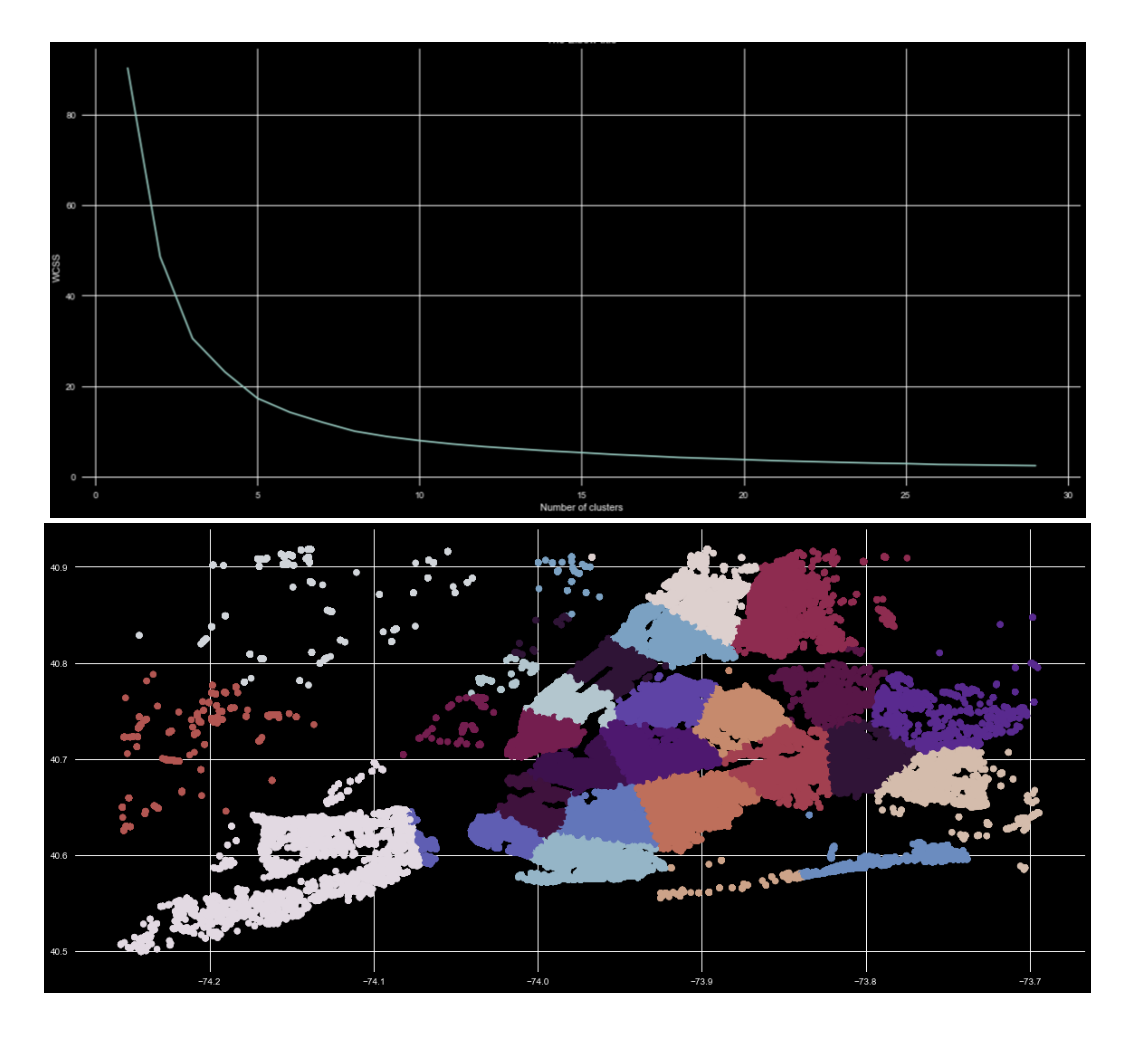
Figure 8. K-means clustering on parking violation data
Overall the model performance is decent. We developed three models for this project. K-means for parking violation and larceny and KNN for precinct classifica- tion. For the parking violation prediction accuracy, we decided to trust the data by just looking at the NYC open data for our model predictions since none of the group member resides in NYC area. The K-means clustering algorithms output clusters that closely resembles the precinct assignments in NYC, showing that the model works well to model the geographical distributions for vehicle crime and parking violation datasets. Although, there is some noise We further adopt the clusters as a means to assign hot zones for each parking meter, use the model for prediction of the safety of the parking spots. The cluster size can be further increased to pin point the hot zones for parking violation or the larceny data. The precinct classification has a accuracy of 88.5% for us to assess the risk level of each precinct, which is a number that we are also comfortable with.
5 CONCLUSIONS AND DISCUSSION
Overall, the project was a success given the amount of time and resources we had. We are able to get the closest parking locations with the recommended safer options. However, there is room for improvement. We are show- ing the level of safety on precinct level, the next step would be to focus on more regional area to provide more accurate recommendation. Also, the application render- ing time can be better, the way the application works is that it communicate with the server every time we perform a search. Even though we already aggregated the data beforehand, the communication time still takes longer than desired.
Further, the cluster zoning not only helps the public to plan their trip safely but can also help the state police and law enforcement department to take additional pre- ventive measures in high and medium crime risk zones to combat against crime and plan advanced investiga- tion strategies. In future, we would like to include more attributes such as time factor to better predict the park- ing availabilities and we can also encompass the entire scope of parking tickets with real-time information on all cars that may have parked in a particular region.
Link to GitHub repository at here.
Acknowledgments
- This project is group project for Georgia Tech Data and Visual Analytics course.