Disaster response classifier
26 Jul 2021This project is aimed at constructing a web-based pipeline to classify messages potentially related to disaster response. If related, the message is further classified into an individual category, such as ‘Request’, ‘Food’, ‘Water’, etc. This
web-based application and underlying machine learning classifier can facilitate disaster response task by deciding whether a message from
sources, such as social media and news, is related. It can help government and non-governmental
organizations to quickly identify needs from areas and people struck by disasters.
Instructions:
-
Access web app deployed at Heroku at:
https://response-classifier-webapp.herokuapp.com/ - File structure of project repository:
├── data ├── DisasterResponse.db # SQLite database containing clean data ├── disaster_categories.csv # raw data containing disaster catergories ├── disaster_messages.csv # raw data containing disaster messages └── process_data.py # ELT pipeline ├── models ├── classifier.pkl # trained classifier └── train_classifier.py # machine learning pipeline to train and store classifier ├── app ├── run.py # Flask file that runs app └── templates ├── go.html # query and classfication result of web app └── master.html # main page of web app ├── images ├── classifying_example.png # screenshot of query classification result page └── index_page.png # screenshot of main web page ├── Procfile # Procfile to run app in Heroku ├── requirements.txt # requirements on packages to be installed to run the web app └── utils.py # utility functions - To run application locally:
- Clone the git repository.
- Run the following commands in the project’s root directory to set up your database and model.
- To run ETL pipeline that cleans data and stores in database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db -
To run ML pipeline that trains classifier and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl -
Run the following command in the app’s directory to run your web app
python run.py - Go to http://0.0.0.0:3001/
- Example screenshots of index page and classification:
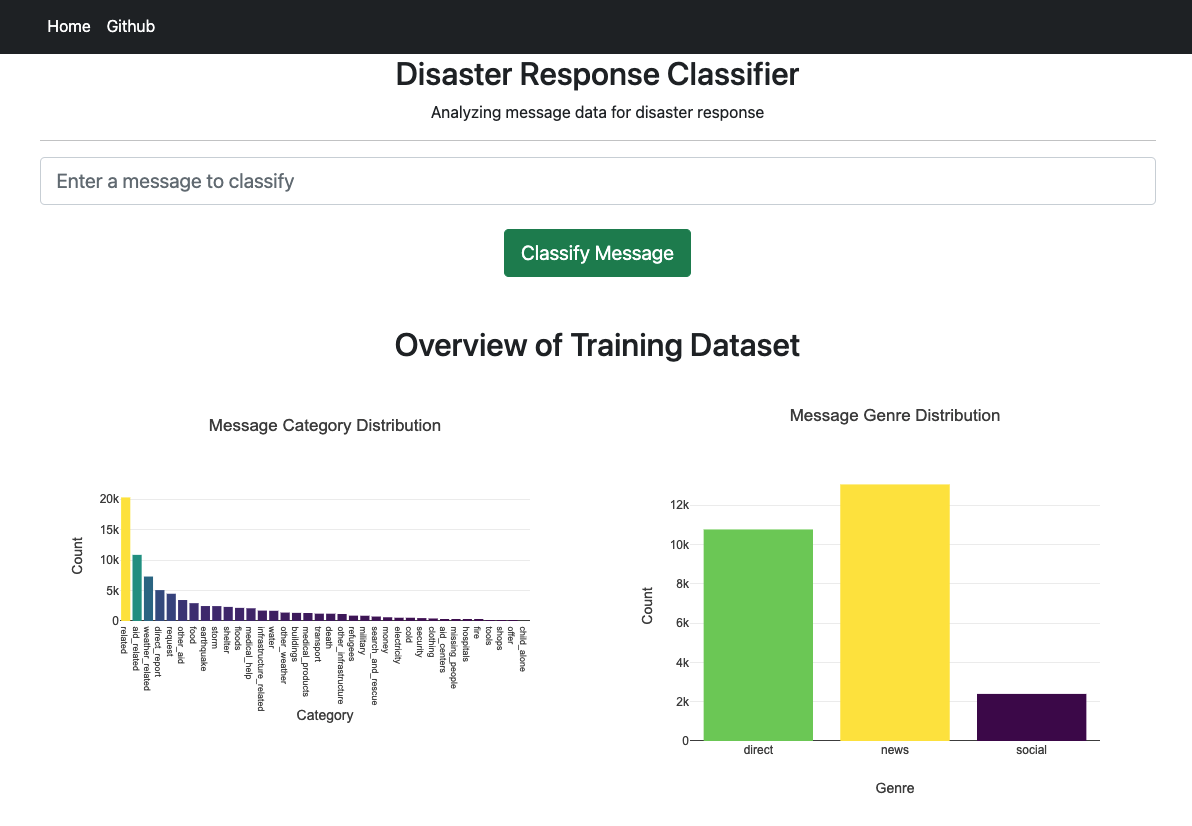
Index Page
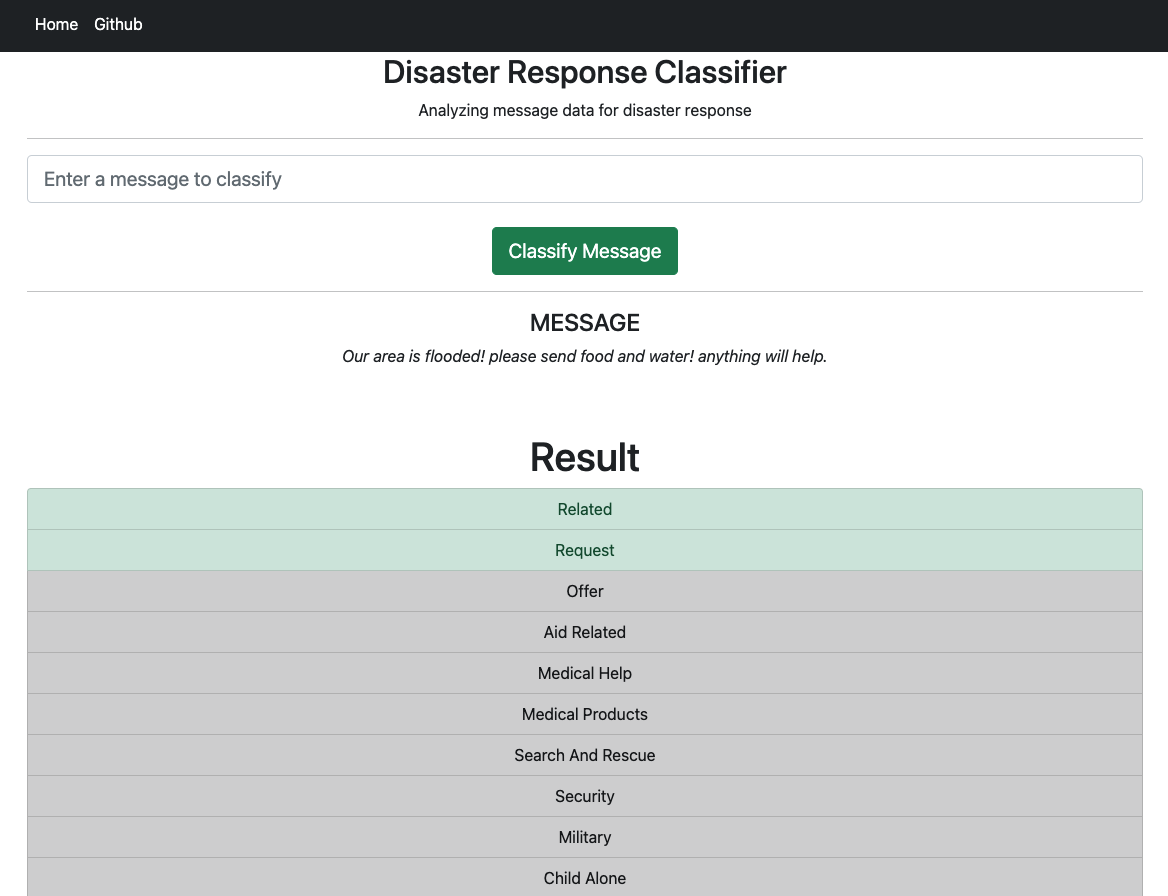
Classification Page
Acknowledgement:
This project was made possible because of the dataset provided by Figure Eight and training from Udacity Data Scientist Nanodegree program.