Use Spark and ML to predict customer churn
25 Aug 2021
Image credit — www.humanlytics.co
What is customer churn? Why it is important?
As defined in Merriam-Webster, “customer churn” , in a business sense, is a regular, quantifiable process or rate of change that occurs over a period of time, due to loss of existing customers and addition of new customers. In most use cases, churn is seen as an indicator of customer dissatisfaction for services and choosing downgrading or canceling subscription. In this sense, churn is directly related to the business growth and profit.
In order to quantify the level of churn, churn rate can be used and calculated as the percentage of customer loss among existing customers for a given period of time. For example, let’s say, at the beginning of a certain month, there were existing customers with active subscription. At the end of this month, 10 customers unsubscribed, and the churn rate for this period is 10%.
Churn rate indicates the rate of losing customers. On the other hand, growth rate tracks the rate of growing customers. These two together determines the expansion or shrinkage for the customer base.
When churn rate is higher than growth rate for a specific product, customer base shrinks over time. Therefore it is important for business to be aware of this measure and formulate appropriate strategy to maintain existing customer base and grow.
It should be noted that, churn rate is a quantitative measure and carries no sentimental meaning. It is up to individual business to find the appropriate level of churn and balance customer flow and revenue growth.
What can data science offer?
Since churn is highly dependent on customer satisfaction, it is possible to use data science tools to analyze customer usage data, extract signals related to customer satisfaction, and use that information to gain business insights.
Statistical analysis can provide overall picture of user behaviors across entire population, and machine learning algorithms will come in handy to predict the tendency of churn for each individual customer.
What is this project about?
Sparkify is a fictional music streaming service similar to Apple Music, Spotify, etc. The dataset provided is in the form of event logs when customers use the streaming services, including artists, songs, geolocation, timestamp, demographic infos, user actions etc.
The main goal of this project is to analyze the event log data and build a machine learning model to predict the users who are more likely to cancel service (churn), and thus use this information in ad campaign to reduce customer out-flow.
In addition, due to the amount of data used, we leveraged spark (pySpark), spark SQL, spark ML and cloud service provided by IBM to perform data wrangling, exploration, and machine learning tasks.
Data exploration
The entire dataset contains 543705 rows, with following columns corresponding to the record from the event log. Among these rows, there are 15700 rows with empty userId from “Logged Out” and “Guest” users. The data set was first cleaned by removing those rows and only considered rows with valid userId.
root
|-- artist: string (nullable = true)
|-- auth: string (nullable = true)
|-- firstName: string (nullable = true)
|-- gender: string (nullable = true)
|-- itemInSession: long (nullable = true)
|-- lastName: string (nullable = true)
|-- length: double (nullable = true)
|-- level: string (nullable = true)
|-- location: string (nullable = true)
|-- method: string (nullable = true)
|-- page: string (nullable = true)
|-- registration: long (nullable = true)
|-- sessionId: long (nullable = true)
|-- song: string (nullable = true)
|-- status: long (nullable = true)
|-- ts: long (nullable = true)
|-- userAgent: string (nullable = true)
|-- userId: string (nullable = true)
Before further exploring the data, it is necessary to define what “churn” means for each user. Related back to the indication of churn as cancelling a service, after obtaining distinct actions in the “page” column (shown below), we define the occurrence of churn event when a user has action of “Cancellation Confirmation”. This definition applies to both paid and free tier customers.
['Cancel', 'Submit Downgrade', 'Thumbs Down', 'Home', 'Downgrade', 'Roll Advert', 'Logout', 'Save Settings', 'Cancellation Confirmation', 'About', 'Settings', 'Add to Playlist', 'Add Friend',
'NextSong', 'Thumbs Up', 'Help', 'Upgrade', 'Error', 'Submit Upgrade']
For users with churn event, users were marked with 1 in a separate column named “churn”. With the definition in place, we can perform more analyses on how Sparkify customers interact with the service based on whether they are churned or remaining customers.
General trend
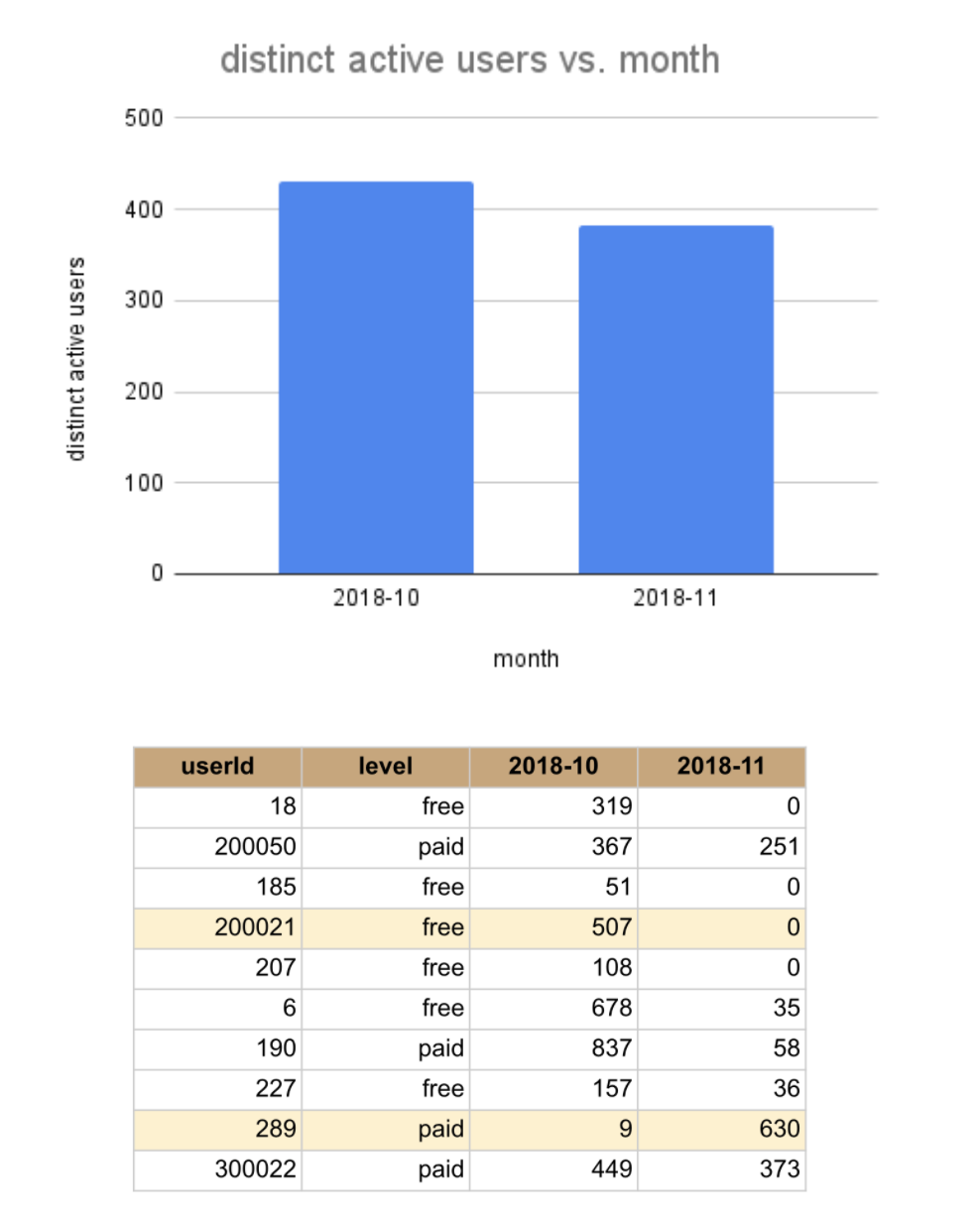
Figure 1. (top) Trend of distinct active users over month. (bottom) Number of actions for selected users in Oct and Nov 2018.
The presented dataset spans from the beginning of Oct 2018 to beginning of Dec 2018. It is helpful to first get an overview of how Sparkify business in terms of month active users.
Figure 1 (top) shows there is a slight drop in monthly active users from Oct to Nov 2018. With the amount of data on hand, it is inconclusive whether this change is significant or not. However, it does signaling the need to look at customer churn. On an individual level, Figure 1 (bottom) shows some users increased service usage from Oct to Nov; others decrease or even not use the service at all.
Churned users break-down by categorical features
The proportion of churned users (churned proportion) among all distinct users is around 0.2210 or 22.10%.
Breaking down churned customers and remaining customers via demographic informations such as gender, it was found that female users have slightly higher churn proportion than male users (p_female=0.2273 vs p_male =0.2160). However, after running two-sided proportions z-test, the difference in churned proportion between female and male users is not significant using a significance level of 0.05.
Similarly, we can break down churned vs remaining customer group by paid or free tiers. It was found free-tier users have slightly lower churn proportion than paid-tier users (p_free=0.2216 vs p_paid=0.2336). After running hypothesis testing, the difference in churn proportion between free-tier and paid-tier users is not significant using a significance level of 0.05.
Churned users break-down by numerical features
The numerical features used in this project were selected from a subset of columns (“ts”, “registration_time” and “page”). Combined with timestamp of churn event, “registration_time” was used to calculate the tenure or customer lifetime in days. “page” column was used to generate user actions with the service, and the total number of each action for each user at each level was aggregated. The following numerical features were used, and selected rows with numerical features is shown in Figure 2. Note: there are multiple users who have been both paid and free users due to upgrade and downgrade events.
'tenure_days', 'total_session', 'total_thumbs_down', 'total_home', 'total_roll_advert', 'total_logout', 'total_save_settings', 'total_about', 'total_settings', 'total_add_to_playlist', 'total_add_friend', 'total_nextsong', 'total_thumbs_up', 'total_help', 'total_error'
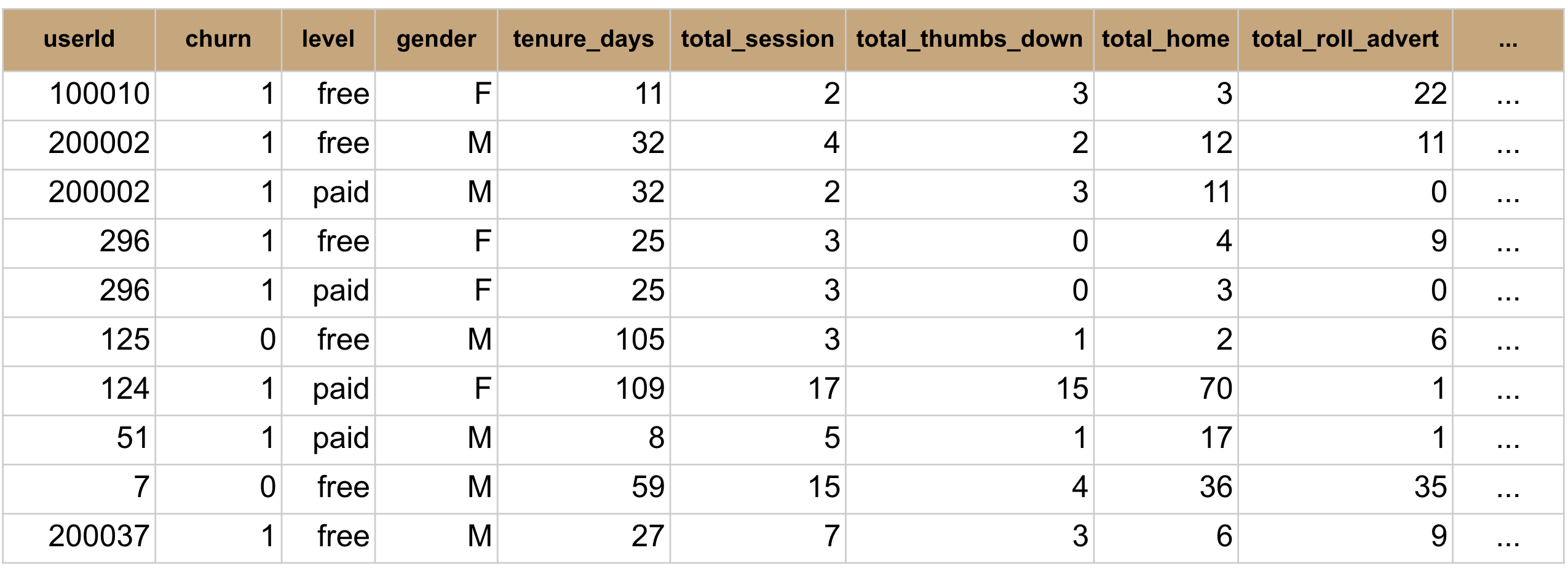
Figure 2. Numerical features for selected row.
First, let’s take a look at the some statistics of these numerical features for churned and remaining users.
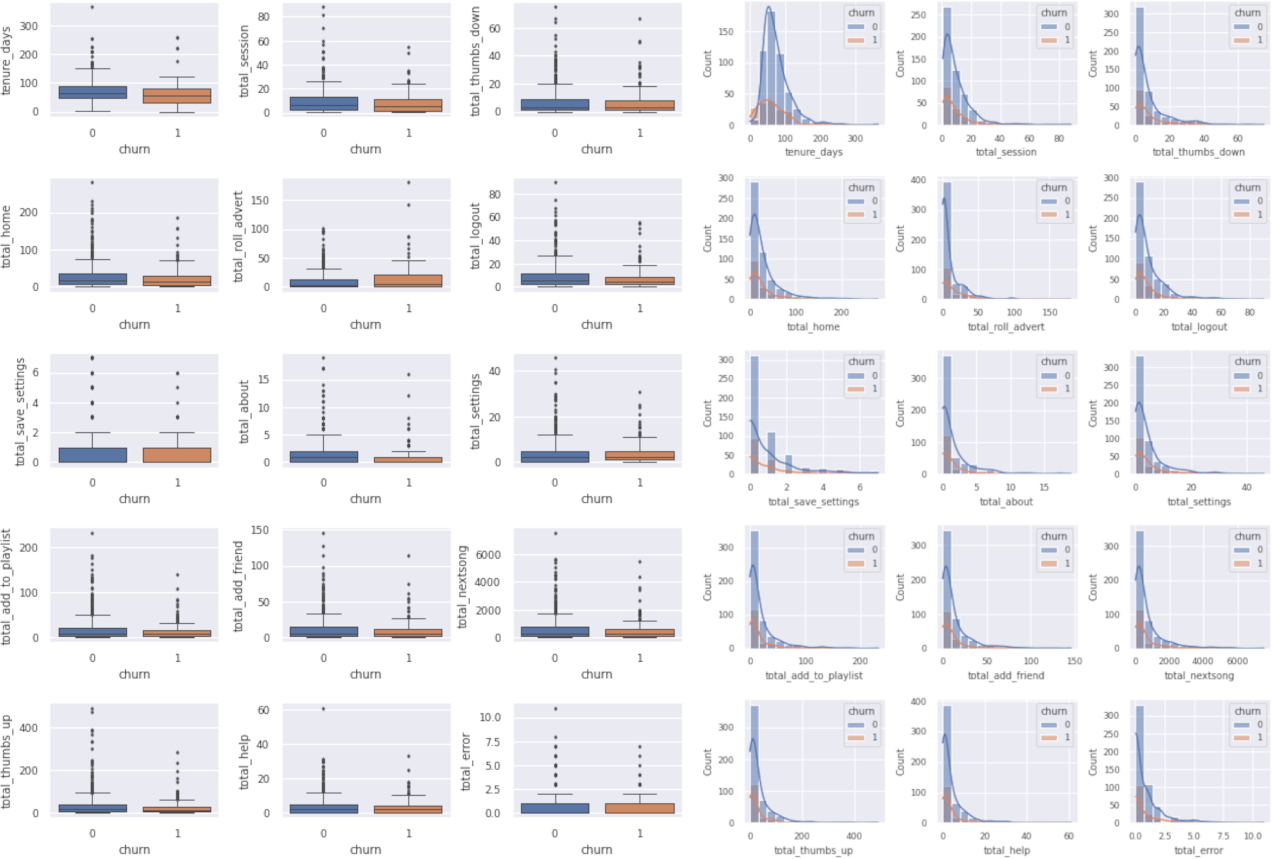
Figure 3. (left) Boxplots showing variabilities and (right) histplots showing distributions of numerical features for remaining (0) and churned (1) users.
Figure 3 shows the variabilities and distributions of these numerical features. The median values for remaining and churned users are similar in all numerical features, and they all have a some amount of outliers signaling skewed distributions.
The skewness is also indicated by the distribution plots. The direction of skewness is also worth studying. For some features, such as tenure days, total_add_to_playlist, total_add_friend, total_nextsong, it would be preferred to have left-skewed distributions with customers staying longer and have more positive engagements with the services. Apparently, this is not the case for the distributions from presented dataset. On other hand, for features like total_error and total_thumbs_down, a right-skewed distribution is preferred signaling fewer negative experiences.
In general, remaining users interacts more with the service across all events compared with churned users. Due to nature of aggregated properties and potential correlation between page actions, it is needed to explore the correlations among different features.
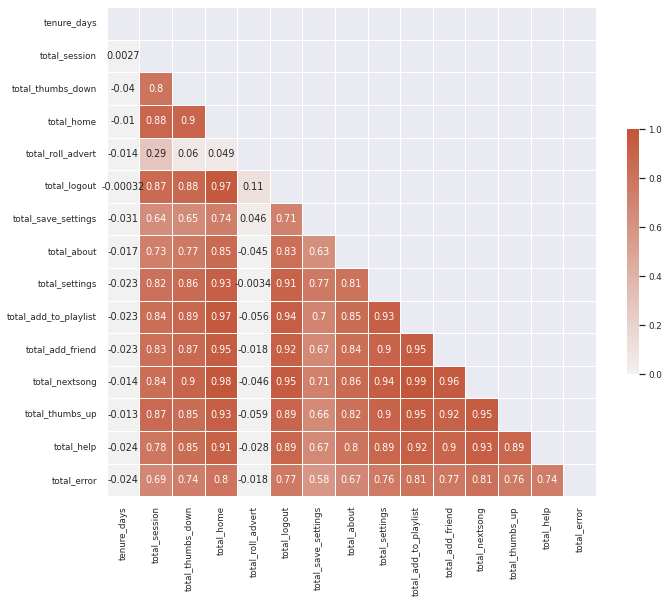
Figure 4. Correlation matrix among different numerical features.
Figure 4 shows the correlation matrix among different numerical features. We could see that strong correlations exists! Proper feature engineering is needed to reduce correlations, in order to reduce multicollinearity and potential issues when using regression models.
Feature engineering
Feature engineering was first performed by normalizing aggregated features by total_sessions. After normalization, obtained correlation matrix is shown in Figure 5.
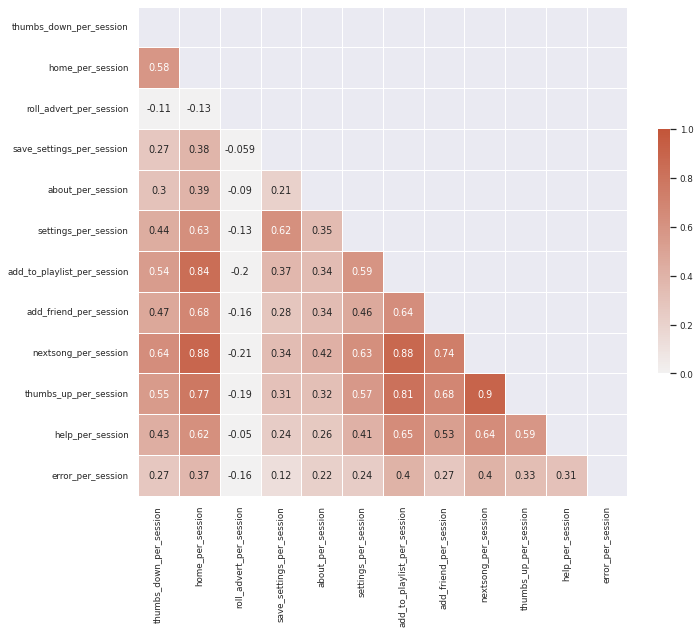
Figure 5. correlation matrix after normalization.
Some features are still highly correlated, such as add_to_playlist_per_session, home_per_session, thums_up_per_session, and next_song_per_session. These are all related to events implying positive user experience. We could add those feature together into a new feature, named postive_engagement_per_session. Updated correlation matrix is shown in Figure 6.
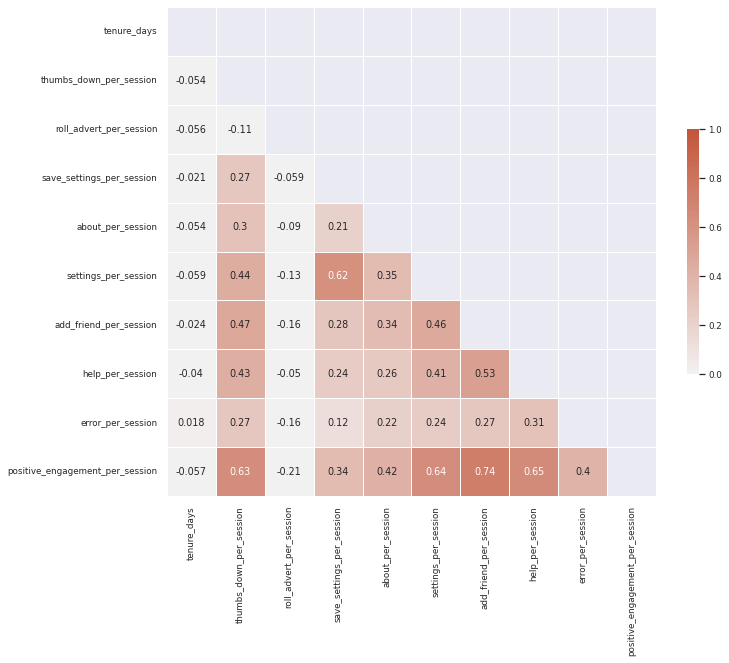
Figure 6. Updated correlation matrix after combining several normalized features.
The numerical features after feature engineering showed less correlation. The transformed data set is then fed into machine learning pipeline to train models to make predictions on customer churn.
Modeling
The transformed dataset was first split into train, test, and validation sets. Several of the machine learning classifiers, including Logistic Regression, Decision Tree, Random Forest, and Gradient Boost Tree, were used for training. Since the proportion of churned users is small compared with remaining users, i.e. imbalanced dataset, F1 score was used as the main measure for accuracy of various models.
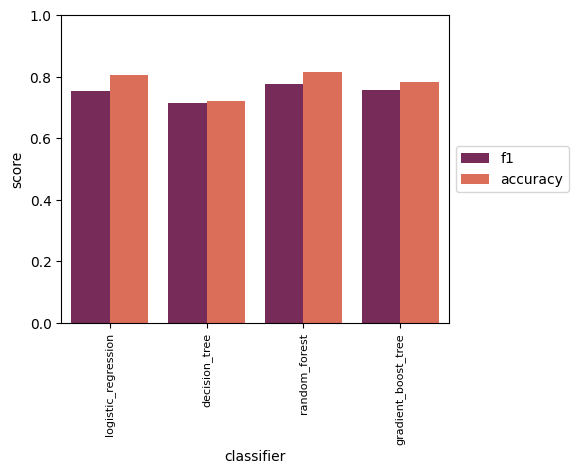
Figure7. Baseline performances of various ML models on validation set.
Before feeding the training set into ML models, feature scaling through standardization was performed. Baseline performances were first obtained for the above models using default settings from Spark ML library. The result is shown in Figure 7.
From the baseline score result, random forest classifier performed the best on validation set with F-1 score of 0.7761 and accuracy of 0.815.
Use the same trained random forest classifier on test set, we got F-1 score of 0.7007 and accuracy of 0.76. To improve its performance, hyper-parameter tuning was performed on this model with 5-fold cross-validation on the training set.
After, hyper-parameter tuning, the performance of the newly trained random forest classifier on test set improved slightly to a F-1 score of 0.7066 and accuracy of 0.768.

Figure 8. Feature importance ranking extracted for tuned random forest classifier.
Feature importance was also extracted from tuned model (shown in Figure 8). Looking at feature importance ranking, we could see that customer tenure time is the most important, followed by user actions, such as receiving ads, thumb-downs, and positive engagements (add to playlist, nextsong, thumbs up). On the other side of the spectrum, gender and level of service are of least importance, which is in line with the hypothesis testing where we conclude the differences are not significant.
Conclusion
In this project, we leveraged Spark to analyze large amount of user logs and built machine learning models to predict customer churn, with the intention of using trained model to be potentially serving future ad campaigns.
By performing hyper-parameter tuning, we achieved slight improvement in F-1 scores on the test set using the tuned random forest classifier. The limited performance improvement might be due to the following reasons:
-
Imbalanced dataset (99 churned vs 349 remaining unique users). Even though we use F-1 score as metric to reduce the bias from imbalanced data, rebalancing could be performed to further improve model performance.
-
Information loss during feature engineering stage. To reduce the multicollinearity, we normalized and combined some features. Even though it could reduce the issues for regression models, it might be worth investigating using features as is for models more resilient to multicollinearity, such as random forest, decision tree.
-
Need for more features extracted from event log. There are more information from the event log that has not been used in this project, such as geolocation tags and downgrade/upgrade related events. These new features could offer more dimensions to correctly predict customer churn.
To see more about this analysis, please direct to my Github repository here.
Acknowledgments
- Datasets are provided by Udacity Data Scientist Nanodegree program
- Cloud service provided by IBM Cloud